As with Oracle, how much you write before a commit has huge effects on performance. If you don't pay attention it takes AGES:
delimiter //
create table tbad (n integer, n2 integer, t varchar(20000), primary key(n))//
create procedure fill1 ()
begin
declare x integer;
set x=0;
while x<50000 do
insert into tbad values(x,x,'bobobobobobobobobo');
set x=x+1;
end while;
end;
begin
declare x integer;
set x=0;
while x<50000 do
insert into tbad values(x,x,'bobobobobobobobobo');
set x=x+1;
end while;
end;
//
mysql> call fill1 //Query OK, 1 row affected (31 min 39.88 sec)
OUCH! 31 minute for just 50K rows!
That's because MySQL has autocommit on by default
Solution is to add something like:
begin
declare x integer;
SET AUTOCOMMIT=0;
set x=0;
while x<50000 do
insert into tbad values(x,x,'bobobobobobobobobo');
set x=x+1;
if mod(x,1000) = 0 THEN
commit;
end if;
end while;
declare x integer;
SET AUTOCOMMIT=0;
set x=0;
while x<50000 do
insert into tbad values(x,x,'bobobobobobobobobo');
set x=x+1;
if mod(x,1000) = 0 THEN
commit;
end if;
end while;
commit;
end;
end;
And this is of course much faster
Query OK, 0 rows affected (3.49 sec)
I often commit about every 1000, but then how much is good enough? I did a test, by writing a procedure to create a test table and fill it up with varying commit bulk sizes.
delimiter //
# this is a result table
drop table if exists zztresults;
create table zztresults(testno int auto_increment primary key,nbrows int,commit_every int, time int);
//
drop procedure testperf1//
create procedure testperf1 (nbrows integer, commit_every integer)
begin
declare x integer;
declare t_start timestamp;
declare totaltime integer;
drop table if exists zztperf1;
create table zztperf1 (n integer, n1 integer, v varchar(2000));
select now() into t_start;
SET AUTOCOMMIT=0;
set x=0;
while x<nbrows do
insert into zztperf1 values(x,x,'bobobobobobobobobo');
set x=x+1;
if mod(x,commit_every) = 0 THEN
commit;
end if;
end while;
commit;
select (now()-t_start) into totaltime;
insert into zztresults values (null,nbrows,commit_every,totaltime);
select totaltime;
end;
//call testperf1(1024000,1)//
call testperf1(1024000,10)//
call testperf1(1024000,50)//
call testperf1(1024000,100)//
call testperf1(1024000,500)//
call testperf1(1024000,1000)//
call testperf1(1024000,5000)//
call testperf1(1024000,10000)//
call testperf1(1024000,50000)//
mysql> select * from zztresults //
+--------+---------+--------------+--------+
| testno | nbrows | commit_every | time |
+--------+---------+--------------+--------+
| 1 | 1024000 | 1 | 870397 |
| 2 | 1024000 | 10 | 14597 |
| 3 | 1024000 | 50 | 1394 |
| 4 | 1024000 | 100 | 703 |
| 5 | 1024000 | 500 | 201 |
| 6 | 1024000 | 1000 | 120 |
| 7 | 1024000 | 5000 | 87 |
| 8 | 1024000 | 10000 | 83 |
| 9 | 1024000 | 50000 | 79 |
+--------+---------+--------------+--------+
So it can take from days, down to a large minute to have a million rows...
Put it in CSV file like this:
SELECT commit_every,time from zztresults
into outfile '/tmp/speed.csv'
fields terminated by ','
lines terminated by '\n'
//
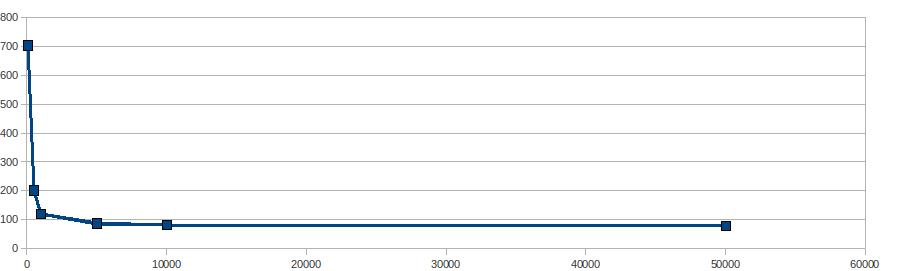
Actually numbers are so exponentially disparate, I used the logarithmic scale on both axis:

-->
| commit_every | time(s) | log(commitnb) | log(time) | |
| 1 | 870397 | 0.00 | 5.94 | |
| 10 | 14597 | 1.00 | 4.16 | |
| 50 | 1394 | 1.70 | 3.14 | |
| 100 | 703 | 2.00 | 2.85 | |
| 500 | 201 | 2.70 | 2.30 | |
| 1000 | 120 | 3.00 | 2.08 | |
| 5000 | 87 | 3.70 | 1.94 | |
| 10000 | 83 | 4.00 | 1.92 | |
| 50000 | 79 | 4.70 | 1.90 |
So in this case with a default MySQL install, I'd go with 5000 commits at once.
What are the cons of using larger sets of commit? In my opinion: Increasing undo space.
On Oracle that would mean the UNDO tablespace could grow or at least internal undo segments.
On MySQL/innodb alike, the rollback segment will grow to hold all uncomitted data. In 5.5 and earlier it is by default inside the one and only tablespace (ibdata)